Artificial Intelligence in Hand and Upper Extremity Surgery Education: Accuracy and Validity of ChatGPT-4o Versus UpToDate as a Learning Tool for Trainees
© 2024 HMP Global. All Rights Reserved.
Any views and opinions expressed are those of the author(s) and/or participants and do not necessarily reflect the views, policy, or position of ePlasty or HMP Global, their employees, and affiliates.
Abstract
Background. The use of artificial intelligence (AI) in medical education has risen rapidly. Trainees can ask ChatGPT-4o (OpenAI) clinical questions and receive management recommendations. Previous studies have assessed the accuracy of ChatGPT, but none have examined hand and upper extremity surgery. This study aimed to evaluate the accuracy of ChatGPT-4o compared to UpToDate (Wolters Kluwer) and categorize the validity of sources provided by ChatGPT-4o.
Methods. Five hand and upper extremity surgery cases were entered into ChatGPT-4o. An UpToDate article was selected for each case. Two hand surgeons and 5 medical students completed a survey comparing the resources. Resources were rated on a scale from 1 to 3, with 1 indicating incomplete information and not useful; 2 indicating semi-complete information and somewhat useful; and 3 indicating a complete answer and useful for management. ChatGPT-4o references were scored on a validity scale of 0 to 2.
Results. Hand and upper extremity surgeons rated ChatGPT-4o and UpToDate as semi-complete and somewhat useful, with median scores of 2.00 and 2.50, respectively. No significant differences were found between resources. Medical students found ChatGPT to provide semi-complete information and be somewhat useful overall, and rated UpToDate more often as providing a complete answer and being useful. However, no statistically significant differences were found between the resource ratings. Of the 25 references provided by ChatGPT, 28% were accurate, 6% were somewhat accurate, and 66% were inaccurate.
Conclusions. The findings indicate overall comparable perceived usefulness of ChatGPT-4o and UpToDate by hand/upper extremity surgeons and trainees. ChatGPT-4o holds promise as an educational tool; however, accuracy concerns remain.
Introduction
Research in artificial intelligence (AI) dates back to Alan Turing’s landmark work in mathematics and philosophy, wherein he considers the question, “Can machines think?” In his 1950 paper, “Computing Machinery and Intelligence,” Turing suggests that humans use information and reasoning to solve problems and proposes that building intelligent machines is possible, as is testing their intelligence.1 Since then, newly developed AI and humans have come face-to-face with the reality of machined cognitive ability, including the defeat of chess grandmaster and World Chess Champion Garry Kasparov by IBM’s DeepBlue supercomputer in 1997, and IBM Watson’s win of $1 million against contestant Ken Jennings on Jeopardy! in 2011.2,3
Games aside, AI has taken on a significant role in the 21st century and is seemingly everywhere. Widespread adoption of AI tools is already commonplace in entertainment, marketing, finance, social media, and technology. Most recently, large language model (LLM) AI has become highly popularized with the notable ongoing development of Meta’s LlaMA, Google’s LaMDA, and OpenAI’s Chat-GPT, the last of which runs on supercomputing infrastructure provided by Microsoft.
The practices of medicine and medical education are not immune to the changes that have accompanied the popularization of AI, including Epic System’s announcement that ChatGPT-4 will be provided to health care providers to help with analysis and drafting message responses in electronic medical records.4 In 2023, it was estimated that ChatGPT had 100 million weekly users and 10 million queries per day.5 ChatGPT-4o is Open AI’s latest LLM chatbot that is trained to respond to human text, audio, or image prompts in a conversational dialogue format. Without any additional tailoring, ChatGPT-4 (the model prior to ChatGPT-4o) was able to pass the United States Medical Licenses Exams 1, 2, 3, and exceeded the passing score by 20 points.6
Medical trainees can enter clinical questions into ChatGPT-4o with nearly instantaneous responses rather than manually searching more traditional, established sources, such as UpToDate (Wolters Kluwer). ChatGPT-4o also has the ability to provide references along with the information it presents. While ChatGPT-4o may increase efficiency in accessing learning resources for trainees, it is important to assess the quality of the responses provided and the validity of the information, as invalid information can put learners and patients at risk.
To our knowledge, this work is the first of its kind to examine an LLM AI as a hand and upper extremity learning tool and compare it to a widely accepted clinical resource. This study sought to evaluate the accuracy of ChatGPT-4o’s responses and categorize the validity of the sources provided by ChatGPT-4o in the context of hand and upper extremity surgery as compared to UpToDate, which is an evidence-based clinical resource.
Methods and Materials
This study aimed to evaluate the accuracy and usefulness of ChatGPT-4o compared to UpToDate in managing hand and upper extremity surgery cases. Five clinical scenarios specific to hand and upper extremity surgery were selected from the Plastic Surgery Case Review Oral Board Study Guide.7 The scenarios were selected to exemplify a broad spectrum of typical clinical cases encountered in hand and upper extremity surgery.
For each case, the prompts "Tell me how to manage ..." and "Give me references at the end of your response" were used to input the information into ChatGPT-4o. For each scenario, the most relevant articles from UpToDate were chosen. ChatGPT-4o responses were accessed on June 7, 2024, and UpToDate articles were accessed on June 9, 2024. This strategy allowed a simple comparison between the AI-generated responses and medical references.
The evaluation approach entailed presenting the responses generated by ChatGPT-4o and the UpToDate articles to a group of evaluators through the web-based survey platform SurveyMonkey (SurveyMonkey, Inc). The evaluators comprised 2 fellowship-trained board-certified hand surgeons and 5 medical students who were tasked with assessing the information's usefulness and completeness in managing the presented hand cases.
The responses were rated on a scale from 1 to 3, where 1 indicated incomplete information and not useful, 2 indicated semi-complete information and somewhat useful, and 3 indicated a complete answer and useful for management.8 Additionally, the accuracy of the references provided by ChatGPT-4o was assessed by 2 reviewers using a scale of 0 to 2.8 A score of 0 indicated that the reference was not available with the described DOI number and source link or was incorrect; a score of 1 indicated that the reference was available with the described DOI number and source link but was not related to the specific topic; and a score of 2 indicated that the reference was available with the described DOI number and source link and was strongly related to the topic.8
Statistical analysis included the calculation of frequencies and percentages for categorical variables, and median (IQR: Q1-Q3) and mean values for numerical variables as descriptive statistics. A Wilcoxon signed-rank test was used to compare the median usefulness scores, and a paired t-test was used to compare the mean usefulness scores for ChatGPT-4o and UpToDate. The statistical significance was set at a P-value of less than .05.
Results
The usefulness of ChatGPT-4o and UpToDate was scored similarly by the hand and upper extremity surgeons. The mean usefulness score for ChatGPT-4o was 2.30, while the median value was 2.00 (Q1=1.75, Q3=2.50). The mean score for UpToDate was 2.30, while the median usefulness score was 2.50 (Q1=2.25, Q3=3.00). Statistical analysis using the Wilcoxon signed-rank test indicated no significant difference in the median scores (P = 1.00). Likewise, the paired t test revealed no significant difference in the mean scores (P = 1.00) (Table 1).
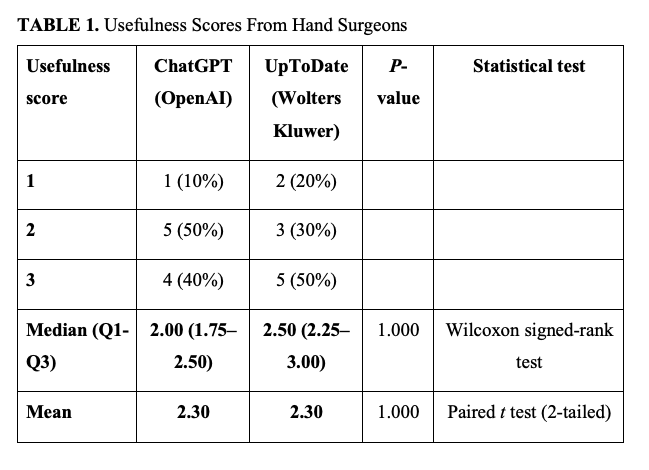
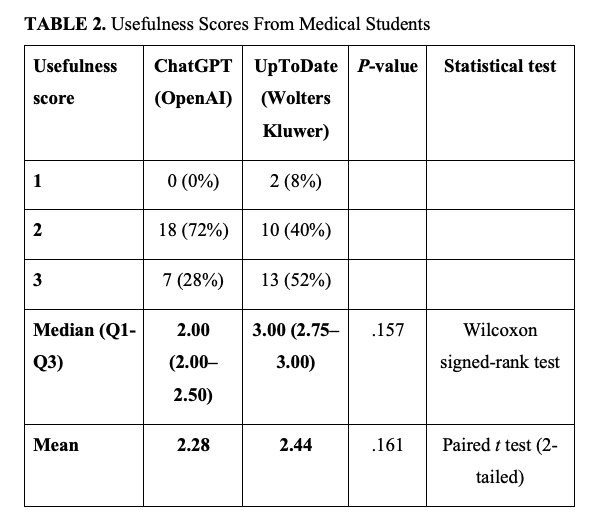
Similar trends were shown after medical students rated the usefulness of ChatGPT-4o and UpToDate. The mean usefulness score for ChatGPT-4o was 2.28, with a median score of 2.00 (Q1=2.00, Q3=2.50). The mean score for UpToDate was 2.44, while the median score was 3.00 (Q1=2.75, Q3=3.00). Statistical analysis using a Wilcoxon signed-rank test revealed no significant difference in the median scores (P = .157). Additionally, the paired t test revealed no significant difference in the mean scores (P = .161) (Table 2).
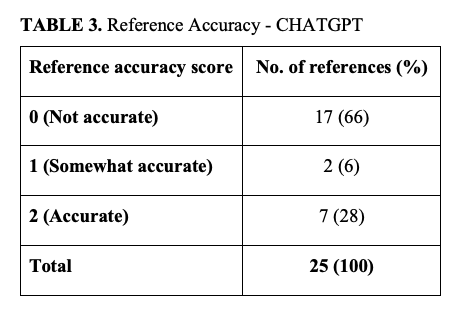
The 2 reviewers also evaluated ChatGPT-4o's references for their accuracy. Of the 25 references, 7 (28%) were determined to be accurate (score of 2), 2 (6%) were somewhat accurate (score of 1), and 17 (66%) were inaccurate (score of 0) (Table 3). The mean reference accuracy score was 0.64, indicating a weak accuracy score.
Discussion
There are several advantages of ChatGPT-4o that draw users to it as a primary educational search engine over other established platforms such as UpToDate. One benefit is that ChatGPT-4o is a free platform, accessible to anyone with internet access, whereas UpToDate requires a paid subscription. Additionally, ChatGPT-4o offers instantaneous responses, while UpToDate is a traditional evidence-based tool that provides a multitude of topic-specific articles that must be manually searched. Due to ChatGPT-4o’s rising popularity in the medical field, it is crucial to evaluate the ability of this new platform to provide appropriate outputs for reliable education and patient care.
In this study, the accuracy and usefulness of ChatGPT-4o for the clinical management of hand and upper extremity surgery cases were perceived similarly to those of UpToDate by hand surgeons and medical students. Notably, this may not always be the case, as ChatGPT-4o can be inconsistent in its reproducibility. ChatGPT-4o’s responses have the potential to vary based on location, data input format (text vs voice), sentence structure, and device.8 ChatGPT-4o is constantly evolving and learning with each human interaction. In this study, we attempted to limit variability by using the same computer on the same day with consistent text-based prompting to generate responses.
A previous study assessed the accuracy of ChatGPT-3.5 in head and neck surgery, concluding that ChatGPT required improvement prior to being used in a medical education setting.8 We employed the same reference accuracy scale in our study and found an average reference accuracy score of 0.64; the score was 0.25 in the aforementioned study.8 A study on breast augmentation had similar concerns with the references provided by ChatGPT, including the suggestion of nonexistent and irrelevant sources.9 Lastly, Grippaudo et al investigated the use of ChatGPT in breast surgery and concluded that ChatGPT should only be used as a supplement to the advice of the surgeon when academic resources are limited, including the lack of references.10
Two-thirds of the references provided by ChatGPT-4o in our study were inaccurate. After evaluating the accuracy of the references provided by ChatGPT-4o, many were found to be nonexistent, with some being falsely conjoined from existing references or author names. Additionally, even references that were confirmed to be real by our reviewers were not all relevant.
LLMs such as ChatGPT tend to “hallucinate,” generating content that is nonsensical or unfaithful to the provided source content.11 These false outputs pose risks to both learners and prospective patients, as the sources and content presented by ChatGPT may seem real but completely lack authenticity, thereby discrediting the resource as a whole.11
The similarity in perceived accuracy and usefulness between ChatGPT-4o and UpToDate represents a landmark achievement for an LLM AI. This highlights a significant opportunity for ChatGPT-4o’s future growth within medical education. Subsequent studies should revisit and retest these findings with each iteration of the LLM AI model. Future versions of ChatGPT may address its current issues with reference accuracy, potentially establishing it as a valuable learning resource.
However, because of reference inaccuracies and the lack of medical evidence for its recommendations, trainees and learners should be cautious when utilizing ChatGPT-4o in relation to any hand or upper extremity case in medical education or clinical settings. In contrast, UpToDate provides accurate, relevant, and evidence-based references, and thus serves as a better outlet for references and sources for further reading than ChatGPT-4o.
Limitations
The results of this study are limited, as only 5 hand and upper extremity cases were evaluated using ChatGPT. Future studies might assess the accuracy of more than 5 cases, as well as investigate other surgical fields and topics. Additionally, the UpToDate articles were hand selected from multiple articles by the researchers, rendering the articles subjective.
Conclusions
Our study demonstrates that ChatGPT-4o and UpToDate are perceived similarly in terms of usefulness by hand and upper extremity surgeons and medical students. While ChatGPT-4o offers promise as an educational tool because of its accessibility and ability to quickly retrieve information, its current accuracy is a significant concern. ChatGPT-4o frequently generated factual inconsistencies, or "hallucinations," including references to nonexistent articles, which limits its reliability.
Despite its potential, ChatGPT-4o cannot yet match the reliability of UpToDate for common clinical presentations in hand and upper extremity surgery. UpToDate remains a dependable evidence-based resource, providing consistently accurate and useful information for trainees.
Acknowledgments
Authors: Caleb Bercu, BA1; Brianna Rosner, BS2; Aneeq Chaudhry, BA2; Hannah Korah, BS3; Isabel Bernal, DO4; Aaron Berger, MD, PhD1
Affiliations: 1Division of Plastic Surgery, Department of Surgery, Nicklaus Children’s Hospital, Miami, Florida; 2Florida International University Herbert Wertheim College of Medicine, Miami, Florida; 3University of Arizona College of Medicine, Tucson, Arizona; 4HCA Florida Westside Hospital, Plantation, Florida
Correspondence: Caleb Bercu, BA; caleb.bercu@nicklaushealth.org
Statement of Funding: The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics: Institutional review board approval was obtained for this study in accordance with a departmental umbrella protocol, with a waiver of informed consent per the institutional protocol; the research was conducted in accordance with the Declaration of Helsinki as revised in 2008.
Disclosures: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
1. Turing AM. Computing Machinery and Intelligence. Mind. 1950;LIX(236):433-460. doi:10.1093/mind/LIX.236.433
2. Deep Blue | IBM. Accessed February 19, 2025. https://www.ibm.com/history/deep-blue
3. Watson, Jeopardy! champion | IBM. Accessed February 19, 2025. https://www.ibm.com/history/watson-jeopardy
4. Epic and Microsoft Bring GPT-4 to EHRs | Epic. Accessed February 19, 2025. https://www.epic.com/epic/post/epic-and-microsoft-bring-gpt-4-to-ehrs/
5. Lammertyn M. 60+ ChatGPT Statistics And Facts You Need to Know in 2024. Accessed October 2, 2024. https://blog.invgate.com/chatgpt-statistics
6. Nori H, King N, McKinney SM, Carignan D, Horvitz E. Capabilities of GPT-4 on Medical Challenge Problems.
7. Woo AS, Bhatt RA. Plastic Surgery Case Review: Oral Board Study Guide. Second Edition. Thieme Medical Publishers; 2020. Accessed August 2, 2024. https://www.wolterskluwer.com/en/solutions/ovid/plastic-surgery-case-review-oral-board-study-guide-14694
8. Karimov Z, Allahverdiyev I, Agayarov OY, Demir D, Almuradova E. ChatGPT vs UpToDate: comparative study of usefulness and reliability of Chatbot in common clinical presentations of otorhinolaryngology-head and neck surgery. Eur Arch Oto-Rhino-Laryngol Off J Eur Fed Oto-Rhino-Laryngol Soc EUFOS Affil Ger Soc Oto-Rhino-Laryngol - Head Neck Surg. 2024;281(4):2145-2151. doi:10.1007/s00405-023-08423-w
9. Seth I, Cox A, Xie Y, et al. Evaluating Chatbot Efficacy for Answering Frequently Asked Questions in Plastic Surgery: A ChatGPT Case Study Focused on Breast Augmentation. Aesthet Surg J. 2023;43(10):1126-1135. doi:10.1093/asj/sjad140
10. Grippaudo FR, Nigrelli S, Patrignani A, Ribuffo D. Quality of the Information provided by ChatGPT for Patients in Breast Plastic Surgery: Are we already in the future? JPRAS Open. 2024;40:99-105. doi:10.1016/j.jpra.2024.02.001
11. Farquhar S, Kossen J, Kuhn L, Gal Y. Detecting hallucinations in large language models using semantic entropy. Nature. 2024;630(8017):625-630. doi:10.1038/s41586-024-07421-0